DeepPhish: Understanding User Trust Towards Artificially Generated Profiles in Online Social Networks

Quick Links
- What are deepfakes and why are they concerning?
- What we studied
- What we discovered
- Our recommendations
- Contact
What are deepfakes and why are they concerning?
The recent progress of deep learning models has significantly improved our ability to synthesize realistic images, video, audio, and text. While such “deepfake” technologies can provide great entertainment by adding Arnold Schwarzenegger’s face to Bill Hader’s impression of him, they also lead to a rising concern in their ability to generate abusive content. Such media can be used to perform advanced social-engineering attacks and has already scammed a CEO out of $243,000 and infiltrated a high-ranking, U.S. political circle.
Prior research has explored automated methods to detect artificially generated content but this can be mitigated by more advanced models and thus turns into a cat-and-mouse game. More importantly, these works do not address the specific contexts of social engineering attacks where human users’ view of the profiles directly affects the success of an attack. We fill this gap by studying user perceptions of deepfake-generated social personas. Via a role-playing scenario, we see whether participants would accept a friend request from a deepfake-generated profile.
We ask:
- How do deepfake artifacts affect users’ acceptance of a friend request?
- How do user warnings/trainings affect users’ acceptance of a friend request?
- What strategies do users use to make to assess a profile?
What we studied
To understand if deepfake profiles can deceive users, we conduct an online user study where participants are instructed to examine three social network profiles, two of which use deepfake images or text. For each profile, participants choose whether to accept or decline a friend request from the profile and are asked to explain their reasoning.
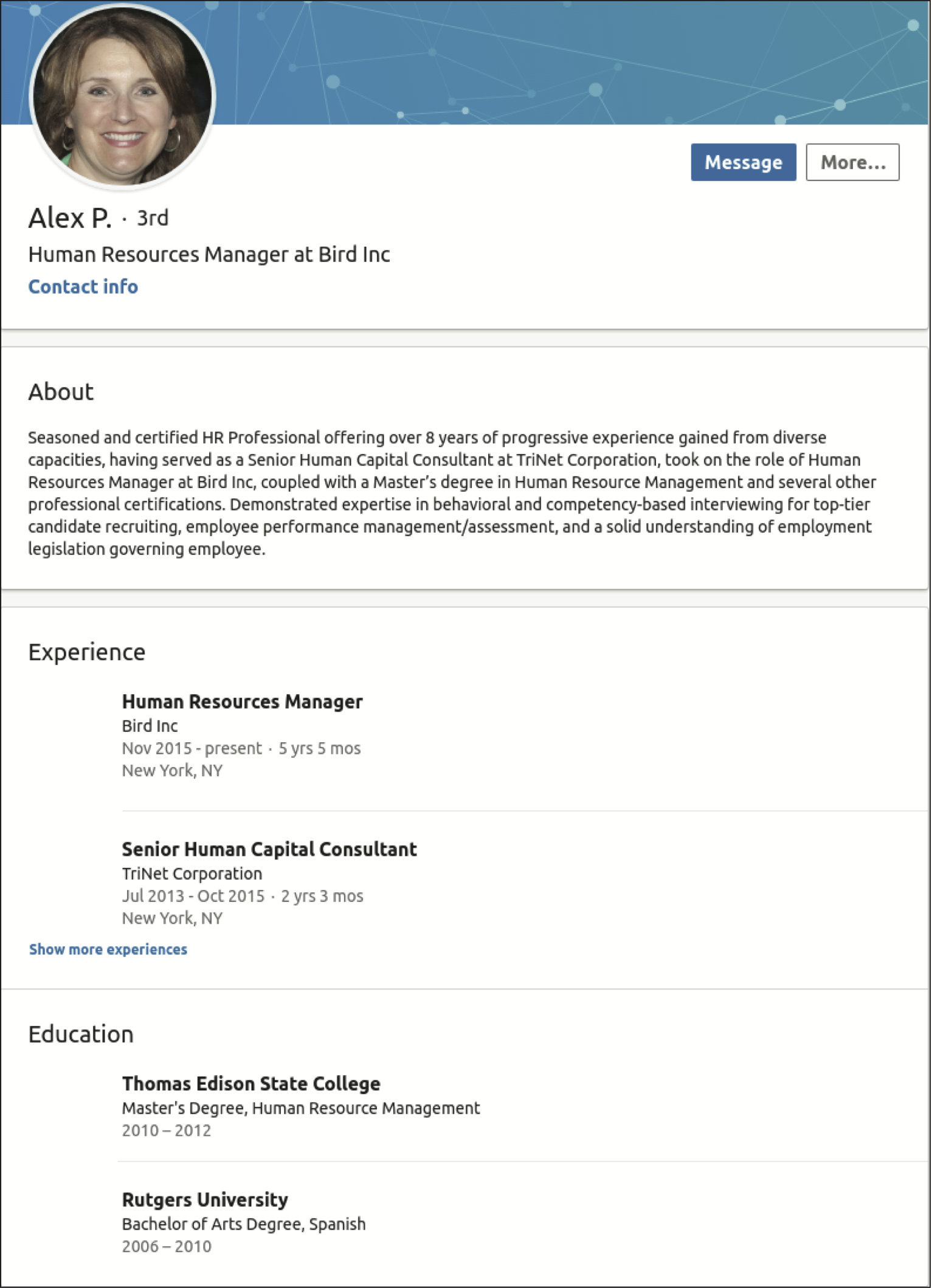
Figure 1: Example Profile Shown - Participants were shown three profiles. Only one was "consistent" -- the other two were deepfakes.
We control two key variables. First, we control “profile artifacts” where we introduce different types of deepfake-generated errors into profile photos, biographies, and in the relationships across profile fields. Second, we control “participant prompting” where we vary the information (warnings/trainings) provided to the participants before they review profiles.
Treatment 1: Profile Artifact
We consider 5 profile conditions where we either present a consistent profile or a profile with one of four deepfake artifacts. Consistent profiles are constructed without using any deepfake content; we use publicly available resumes for text content and publicly available human-face dataset for profile images. Artifact profiles are constructed using real outputs and inconsistencies that commonly arise from state-of-the-art deepfakes models. We use StyleGAN2 for profile images and GPT2 for the “About” section.
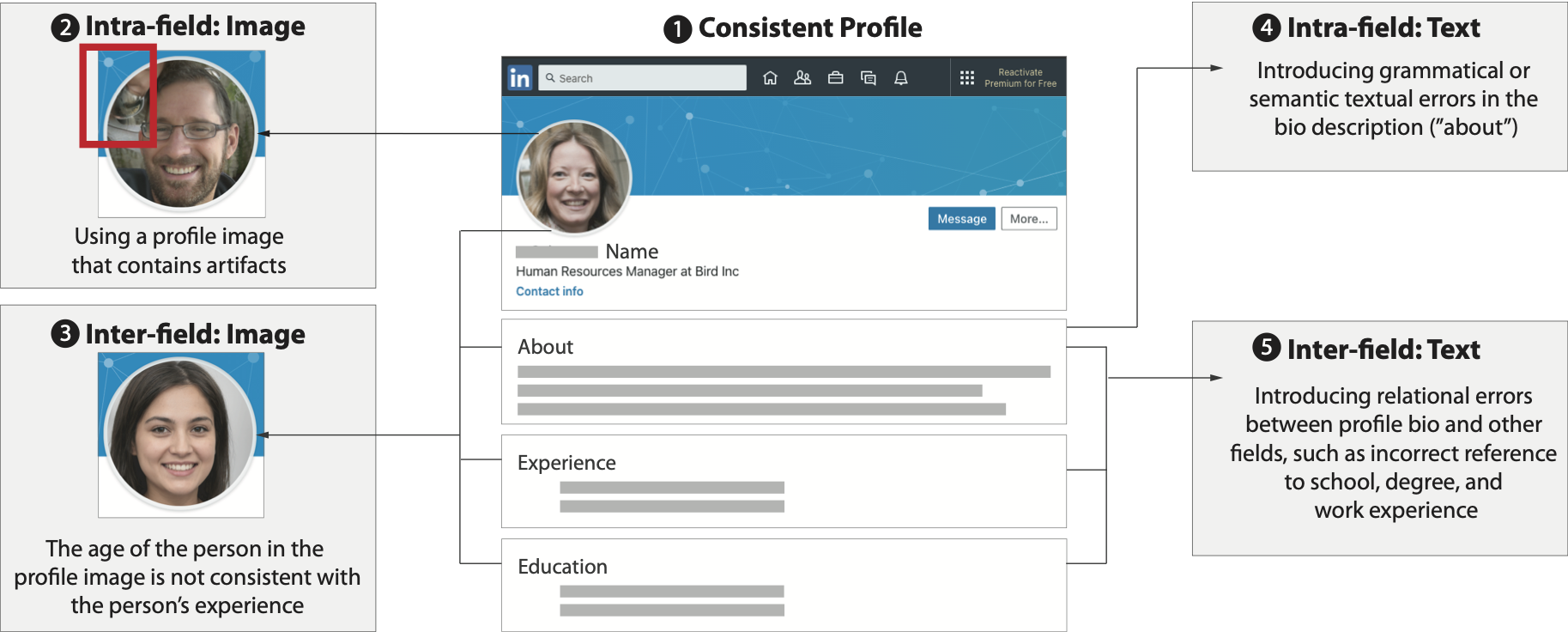 Figure 2: Profile Artifact Conditions – We have 5 conditions: 1 consistent profile condition and 4 conditions with deepfake artifacts.
Figure 2: Profile Artifact Conditions – We have 5 conditions: 1 consistent profile condition and 4 conditions with deepfake artifacts.
As different types of artifacts may result in different responses from human users, we investigate two intra-field inconsistencies that are the result of isolated mistakes within the free-form text summary and the profile image, and two inter-field inconsistencies that are the result of semantic differences between a generated data field and another profile field.
Treatment 2: Participant Prompting
Participants are also exposed to one of three different prompt levels where they receive different information about deepfake profiles and artifacts. These were made to emulate possible user warnings or trainings a social media site may provide.


Figure 3: Hard Prompt Training – Participants are shown one of three different prompts before reviewing profiles. Displayed are a few image and text artifacts shown to participants in the "Hard Prompt" condition.
- No Prompt: We do not mention that the profiles could be algorithm generated nor ask users to look for potential artifacts.
- Soft Prompt: We inform the participants during the tutorial that some profiles may be fake, i.e., generated by Artificial Intelligence. However, we do not provide specific information on what fake profiles look like or how to detect them.
- Hard Prompt: We inform the participants that some profiles may be fake and include a detailed tutorial that describes deepfake techniques and common artifacts in generated images and text.
What we discovered
We analyzed the results of 286 participants and discovered a number of useful insights, a few of which we will now highlight.
People are overly trusting of deepfake profiles
Under the condition that resulted in the lowest acceptance rate which contained a detailed training of what deepfake image artifacts look like, 43% of participants still accepted the connection request. Under other conditions that contained deepfake-artifacts, participants acceptances range from 56%-85%. Thus, even in the best case scenarios, participants are still largely vulnerable to deception by deepfake profiles.
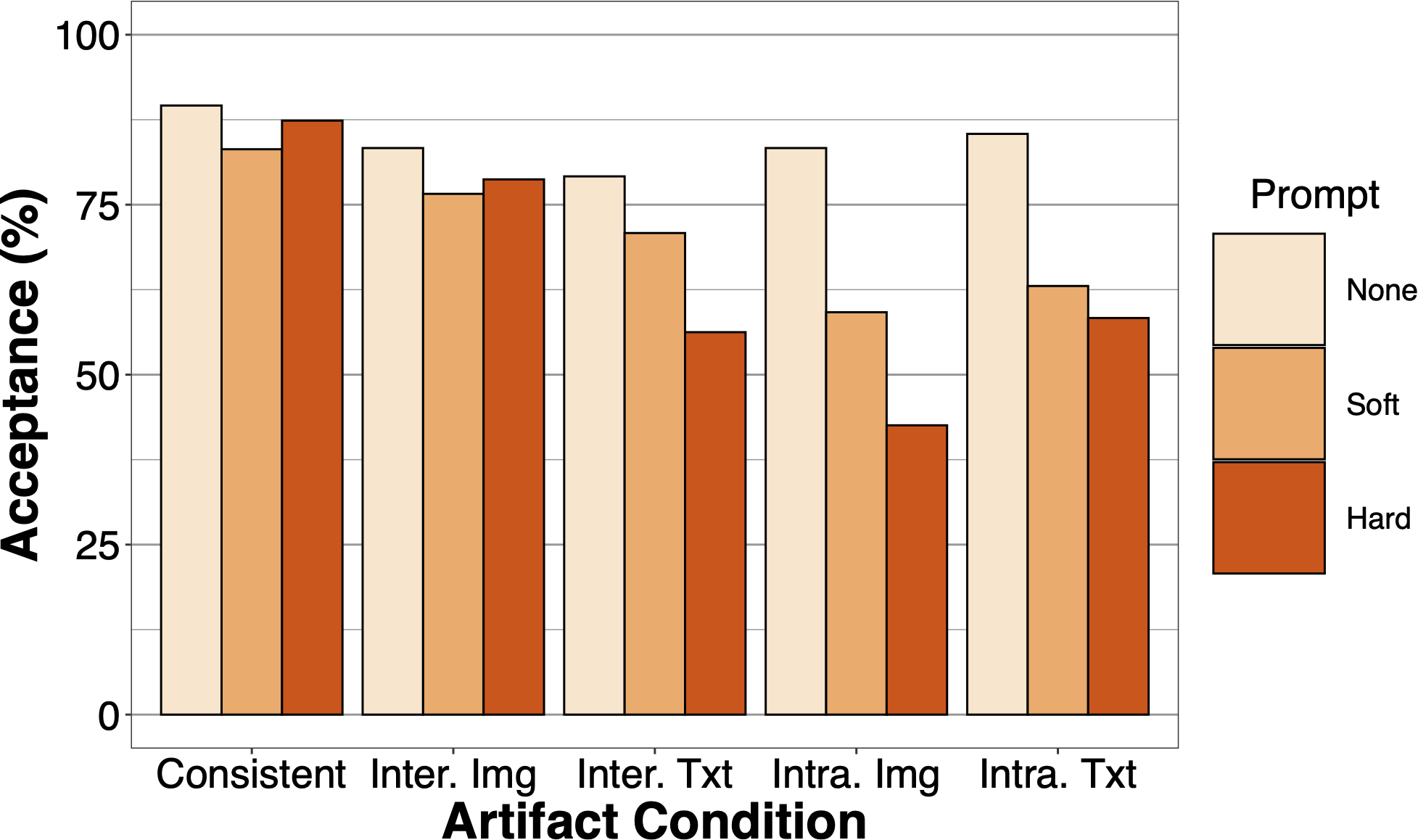
Figure 5: Request Acceptance Rate – Profiles’ request acceptance rates under different prompt/artifact conditions
Figure 4 shows the acceptance rate broken down by prompt level and artifact condition. For No-prompt condition, the consistent profiles have an acceptance rate of 90%, a rate that we expect given prior studies on natural profile acceptance; however, we also notice that the acceptance rates of deepfake profiles are also fairly high (79%–85%). For Soft- and Hard- prompt conditions, the acceptance rate appear to be lower with acceptance rates between 43%-71% for profiles with intra- field image, intra-field text and inter-field text artifacts. While we find that both prompting and profile artifacts significantly decrease the likelihood of acceptance, these reductions appear largely insufficent to protect users.
Certain deepfakes artifacts are harder for people to detect
We observe that the text and image artifacts (intra-field) appear to have different effects. Even after a deepfake warnings, participants often have difficulties to tell whether the text artifacts are results of deepfake algorithms or due to poor writing/communication skills of the individual. In contrast, after prompting, it is easier for the participants to attribute image artifacts because there are no other plausible explanations.
While intra-field text artifacts were noted in some responses (n=19, 13%) participants often attributed the artifacts to a lack of communication/writing skills. One unprompted participant mentioned: “his About section is honest, but it contains extraneous information that make him seem less interested in putting out a career focused LinkedIn profile” (P189) while one prompted participant noted: “the description is repetitive and doesn’t seem all that intelligent or knowledgeable” (P59). In contrast when intra-field image artifacts were also noted (n = 30; 21%) prompted, participants often immediately identified them as signs of artificial profile, e.g., “the picture is very off - this looks like an AI-generated picture to me” (P215) and “the hair is very weird and seems AI like” (P51). Thus while both text and image generation models produce noticeable artifacts, they differ in their attributability.
Warning people about deepfakes may cause anti-social behavior
When presented with deepfake warnings, participants sometimes overcompensate in the process of searching for deepfake artifacts, which leads to mistakes such as perceiving artifacts that do not exist. Not only does this have the potential to affect real users, but we find evidence that such judgements may be informed by stereotypes which target marginalized communities.

Figure 6: Unexpected Artifacts noted in Consistent Profiles – Examples of real image/text recognized as generated ones by
some participants.
While prompting did not result in a significant differences in the trust of consistent profiles, we observe that prompted users occasionally perceive qualities within real images/text as signs of algorithm-generated artifacts. One example image is shown in Figure 6a). A hard-prompted participant misinterpreted the shoulder of another off-image person as algorithm-generated artifact: “There is something wrong with the applicant’s photo…the detail of one of her shoulders is impossible” (P224). In the same image, another hard-prompted participant noted a small glint on a tooth (likely due to a cavity) and became suspicious: “There is a little glitch in the corner of her mouth that makes me wonder if an AI made the photo” (P111). We found similar comments about human-made texts that was free of any major errors (Figure 6b).
Importantly, we also find evidence that perceived artifacts stemmed from racial and gender expectations. In one image that depicted a woman of African descent, several participants perceived a disagreement between the name and the demographics of the subject. Two soft-prompted participants noted that “the picture shows a black woman but the name seems to belong to a white man” (P68) (the name was Chris), and “the name also doesn’t suit the person in the image” (P141) (the name was Alex). Similarly for a white man with the name “Lee”, one hard-prompted participant noted that “the name is [of] Asian [descent], but the pic doesn’t match” (P202). The result suggests that after prompting, users may overcompensate in the effort of looking for algorithm-generated artifacts, and potentially begin to make judgments based on stereotypes. Such behaviors could lead to disproportionate distrust towards real people that differ from one’s stereotypes of others. Ultimately, further research is needed to investigate these observations.
Our recommendations
 Figure 7: Soft Prompt Warning – Even with a light warning shown here, we see both the positive effect of increased deepfake protection and negative effect of anti-social behaviors emerge.
Figure 7: Soft Prompt Warning – Even with a light warning shown here, we see both the positive effect of increased deepfake protection and negative effect of anti-social behaviors emerge.
Our study shows a mixed result with respect to potential intervention strategies for end-users. While we should that user warning decrease user’s acceptance of deepfake profiles and encourages users to focus on noticeable artifacts, we also discover a spillover effect. While there is no statistically significant evidence that warnings affect user trust of consistent profiles, we find multiple instances where participants discredited legitimate users after reading deepfake-related tutorials. Even more concerning, this behavior may disproportionately affect certain user populations. Thus, we do not currently recommend social media platforms adopt user warnings about deepfakes.
Instead, we provide suggestions for platforms to take action before deepfake profiles reach end-users.
Deepfake profile detection:
Existing deepfake detection methods often only focus on a specific media type, thus there is an opportunity to build detectors based on inter-field inconsistencies across media modalities. From the attackers’ perspective, fully addressing inter-field inconsistencies using generative models is challenging. These challenges for attackers mean opportunities for defenders.
Moderation:
While community-based moderation has played a big role in platforms such as Twitter and Facebook, our results indicate that this is challenging as only some users are capable of effectively distinguishing deepfake profiles; however average users at are likely to fail this detection task. In particular, it is difficult for average users to disentangle honest mistakes from generative errors when dealing with texts, a major component of most platforms’ content. To enable effective moderation, one possible direction is for social media platforms to identify capable users and appoint them as community moderators.
Additional measurements of Deepfake Profiles:
Finally, developing effective countermeasures requires understanding how deepfake profiles are (and will be) used in practice. So far, empirical investigations suggest that real-world deepfake profiles are not (yet) used for large-scale attacks but are often used for targeted purposes. This means detection methods that focus on clustering large groups of similar accounts/profiles are likely to be ineffective. However, these investigations are focused on specific campaigns and may not be representative. More systematic measurements on deepfake profiles are needed.
To learn more about our study, please check out our USENIX Security 2022 paper!
Contact
This work is by Jaron Mink, Licheng Luo, Natã M. Barbosa, Olivia Figueria, Yang Wang, and Gang Wang. If you have any questions, please feel free to contact Jaron Mink at jaron.mink@asu.edu.
[1] Tero Karras, Samuli Laine, Miika Aittala, Janne Hellsten, Jaakko Lehtinen, and Timo Aila. Analyzing and improving the image quality of StyleGAN. In Proc. of CVPR, 2020. [2] Radford, Alec, Jeffrey Wu, Rewon Child, David Luan, Dario Amodei, and Ilya Sutskever. Language models are unsupervised multitask learners. OpenAI blog, 2019.